CaptureBites MetaServer Version History
You can always download the latest version of MetaServer including Operator, Admin clients and sample workflows on the MetaServer Product Page. If you are looking for base installers without any sample workflows, please refer to our download page.
IMPORTANT: Before refreshing or updating your MetaServer, please pause your MetaServer first. You can do this in your Admin Client, under the Server tab. As soon as all your action queues are "yellow" (= paused), you can perform your refresh or update.
This will ensure that no documents in your current queue become corrupted during your refresh or update.
IMPORTANT: If you are updating from a MetaServer version lower than 3.1.3
IMPORTANT: If you are updating from a MetaServer version lower than 3.1.3, it is possible that a Computer ID mismatch can occur.
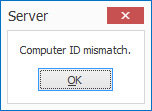
On most systems, the update will not cause any problems. However, occasionally, on some systems this may cause a Computer ID mismatch after upgrading. To fix this issue, please refer to the Computer ID Mismatch troubleshoot page.
IMPORTANT: If you are updating from a MetaServer version lower than 3.1.1
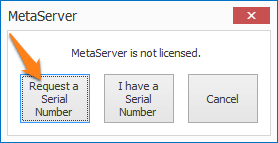
IMPORTANT: If you are updating from a MetaServer version lower than 3.1.1, a pop-up window will ask you to request a serial number. If you haven't received a serial number already, please press the "Request a Serial Number" button and fill out the form. We will send you your serial number as soon as possible.
Please also note that old MetaServer activation codes (e.g. "K-123F0-12345-123B4-CD12B-C0D12-E1EB2") are not compatible with this version and future releases of MetaServer. You can apply for a replacement serial number through our online request form.
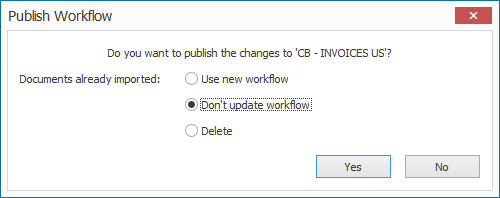
IMPORTANT: If you are updating from a MetaServer version lower than 3.0.23
IMPORTANT: If you are updating from a MetaServer version lower than 3.0.23, it is required to republish existing workflows. Select each of your workflows, make a small change, like adding and removing a space to the workflow description, and publish the workflow. If there are documents already imported in the workflow, then you do not have to apply the changes to these documents.
Version 2.0(24) | 2018-12-12
NEW: Convert To Black and White action:
The setup of the Convert to Black and White action is similar to the Extract Text setup viewer but only showing the black & white conversion settings.
The pages selection and conditional settings make it possible to conditionally convert specific pages or documents to BW based on index values. For example If the field “document type” is equal to vendor “FUZZY PRINTING INC”, then those documents will be converted to black & white.
As usual, the result would be exposed as Processed PDF or Processed TIF in the exporters.
Version 2.0(23) | 2018-12-12
ENHANCEMENT: When you test extraction rules, the OCR result is saved as a *.ExtractTxt file. These files are now using a new .XtrTxt file extension. If you sort them by extension the are placed on the bottom of file list so you cannot accidentally copy them in place of the PDF files when testing your workflows.
FIX: Extract: Extract Text Rule: The image was not displayed in black and white anymore when doing TEST. The test result is also not reused anymore.
FIX: Convert to Format: Convert to TIF: Failed on Black and White PDFs or ePDFs containing images in black & white (eg signatures in electronic Floating data documents).
Version 2.0(22) | 2018-12-10
ENHANCEMENT: Improved .Net Heap Memory management. Important for systems handling many documents per day.
ENHANCEMENT: Moved Apply Separation action to a seperate *.exe to improve memory management.
FIX: Opening the document list is now much faster.
ENHANCEMENT: Updated Email and FTP libraries to Rebex 2018 R3 Build 6874.
Version 2.0(21) | 2018-11-20
ENHANCEMENT: Reset the windows garbage collector every 100 lookups.
ENHANCEMENT: Possibility to decrease the MetaServer queue to a lower value than 250
FIX: Document set locking to avoid concurrent use.
NEW: MFP Panel updated with Questionnaires instead of POD workflow
This version was never made public and only tested in beta at some customers (CLL & EAD).
Version 2.0(20) | 2018-11-14
ENHANCEMENT: Improved prority handling of separated documents. Previous versions could cause a slow down or complete shut down if large volumes of documents were separated.
ENHANCEMENT: Better error handling: Find / Lookup / Stored Procedure: list procedures: report error if a parameter data type is unexpected
Version 2.0(19) | 2018-11-14
ENHANCEMENT: Improvement in the way delayed validate is handled. Delayed validate is used to allow a validation operator to go back one document to make correction.
Before documents were processed chronologically and got delayed even if the delay was already expred because following a document being delayed. Now documents are processed according to their delay expiration time and documents cannot get held up anymore because there is a document before being delayed.
FIX: Apply Organize: Assign a copy of the field values to the new documents (fix for “Collection was modified; enumeration operation may not execute.”). MS_Workflow.Document.WfDocument.SerializeFieldValues(TextSerializer writer, IDictionary`2 fieldValues)
Version 2.0(18) | 2018-11-09
ENHANCEMENT: The Convert to Searchable PDF is now running multi-threaded and runs 4 converter threads. Expect a speed enhancement between a factor 2 to 4 depending on the peformance of your processor.
ENHANCEMENT: Better overall memory management
Version 2.0(17) | 2018-11-08
FIX: SQL Direct: DB Lookup: Fixed a problem handling integers.
NEW: Conversion of email body to PDF is now possible. However, this works with limitations. You can import emails, convert the body to PDF and export those PDFs to folder. You cannot do anything in between.
In the Export to Folder action, select Email PDF as the File Source to export the email body as PDF.
You cannot extract or validate after a “Convert Email Body to PDF” action. You would need to export the converted PDFs to another workflow’s watched folder to do extraction and validation etc.
Version 2.0(16) | 2018-11-07
NEW: We added a direct connection to SQL Server for all functions using a DB connection in MetaServer:
– Find Word using words from database
– Validation Database Lookup
– Export to Database.
When you use a direct SQL Server connection, you don’t require the setup of an ODBC data source anymore on the server or on any of the validation clients.
Because the communication with the SQL server is direct, searching and updating SQL tables is also more efficient.
Currently, only MS SQL Server is supported.
Version 2.0(15) | 2018-11-05
FIX: Validation: DB Lookup: If a lookup was used with the option “check if multiple hits” and the lookup was filtered, then, even if filter returned a single hit, the field still stopped in Validation because of multiple hits.
FIX: Extraction: Stored Procedure: If no Stored procedure was selected, the Connect button did not open the Stored procedure tab. This typically happened when you had defined a stored procedure rule from scratch.
Version 2.0(14) | 2018-11-01
NEW: Lookup with Stored Procedure. You can now call MS SQL or My SQL stored procedures and use the returned results in MetaServer. This action can be found under the Find rules.
For example, if you have a list of expected documents for each case in a SQL table, then you can create a Stored Procedure that checks presence of a scan date for each document. If a scan date is present for all documents, the procedure can then return a value TRUE for completeness, if any of the expected documents don’t have a scan date, the procedure returns a value FALSE for completeness.
Based on the returned value, you can then trigger a notification email if all documents have been scanned.
Version 2.0(13) | 2018-10-22
NEW: Integration of a new version of the OCR engine used for Text extraction. This version can recognize an extended character set including characters used by East European countries and Russia (Cyrillic).The new OCR engine also uses the selected language to improve OCR accuracy.Because the previous version of the OCR engine did not have a language setting, we use the Windows language to set the language when converting existing workflows to the new version. We recommend the settings of your “Extract Text” rules to be sure the adjusted settings match your configuration.
Version 2.0(12) | 2018-10-08
NEW: Convert / Convert to Format action. With this action you can convert PDF files to Multipage TIF. The Multipage TIF output is exposed in the Exporters as “Processed TIF”. This to be roadmap compatible when we introduce importing TIF files. The original imported TIF will then be accessible as Imported TIF in the Exporters.The TIF format is available in the Export to Folder and Export to Email actions.We will add TIF support to future connectors as they get releases.
NEW: Edit / Scale Page(s): With this new action, you can first extract data from a 300 DPI or 400 DPI scanned document, create a searchable PDF and at the very end scale it to a lower resolution for storage. In other words the high resolution version will be used to get the best OCR result and when all data extraction is done including creating the PDF searchable text layer, the image size is reduced. This only affects color scans and does not touch black and white scans or electronic PDFs. The Scale Page(s) action also allows to set the JPG Quality factor. Default JPG Quality = 82
ENHANCEMENT: Export to Database: This version includes up to 5 DB connection retries if the connection fails, with a 0.5 sec delay between them.
FIX: Export to Email: When the user did not put a file extension in the email attachment name, the MetaServer showed an error because of the missing MIME type. Since this version, the mime type comes from the selected file type if there is no extension specified.
Version 2.0(11) | 2018-09-28
ENHANCEMENT: Convert to Searchable PDF: We adjusted the logic to determine if a PDF should be converted to searchable PDF.
The logic is now: If the PDF only contains a single image and no text, a searchable PDF will be generated.
That means that:
– Text based electronic PDFs are not converted and remain untouched
– PDFs that are already searchable are not converted and remain untouched
– MRC (Super Color Compressed) PDFs contain multiple layers of images instead of a single image and are not converted and remain untouched.
For Extract Text to determine if a PDF is image only, nothing has changed except of considering a bit more margin (+1mm / -1mm) of the scanned image versus the PDF page size.
Convert to Searchable PDF: If nothing is entered in the page range, “Page(s): All” is displayed in the Actions list, otherwise the selected page range is displayed.
Version 2.0(10) | 2018-09-21
NEW: Convert to Searchable PDF action: You can now convert image based (scanned) PDF files to searchable PDF files.
To get access to the feature, you need to install the MetaServer Searchabe PDF module which can be downloaded from here:
https://www.capturebites.com/downloads/CaptureBites_Windows_MetaServer_-_Searchable_PDF_3.0.exe
You basically add a Convert to Searchable PDF action to your workflow before Export. In the Export action, you then select “Processed PDF” as the PDF you want to export.
Version 2.0(8) | 2018-08-28
NEW: VARIABLES IN THE DOCUMENT SECTION: “Document Number” and “Document Count” in set. A set is a single PDF with multiple documents. After separation, manual with the organizer or automatic with a Document Separation action, these variables are updated with the total number of documents after separation and the document number of each document.
FIX: Find Word with Mask / Words in combination with “Accept words from database” was not accent agnostic, requiring to put all variations of accented words such as: PROCÈS-VERBAL, PROCES-VERBAL, Procès-Verbal in the DB. The search is now accent agnostic and you only need to put one variation. However this is only valid for MetaServer databases.
Version 2.0(6) | 2018-08-27
FIX: Document Separation: If you add a separation point manually after automatic separation a red error occurs.
FIX: Field values were lost after going through the organizer.
Version 2.0(5) | 2018-08-21
ENHANCEMENT: Mark Detection: Faster processing when multiple mark detection rules are defined on the same page. Example: A questionnaire with 80 questions with each 5 options (a total of 400 check boxes to evaluate) took about 200 seconds to process before and now takes 35 seconds.
Version 2.0(4) | 2018-07-23
NEW: Mark Detection: Mark detection allows to detect check marks or detect pixels in a large box like in a signature zone.
To get familiar with this new extraction rule, please try out the new CB – QUESTIONNAIRES and CB – PARKING VIOLATIONS demo workflows. Online help will follow soon.
Version 2.0(3) | 2018-07-19
FIX: Validation text selection tool on electronic PDFs did not work correctly anymore in 2.0(2). Selecting a zone, selected all the text on the page.
Version 2.0(2) | 2018-07-18
NEW: New option in the Separate Document / Process action: “Rotate page like text in field…”. Just select a field with extracted text by means of OCR or bar code recognition and the page will be rotated according to the orientation of the majority of the text contained in the field.
NEW: In the About tab in the backstage you now have a Version History button which opens the online version history page
ENHANCEMENT: Separate Document / Process Page: When a new action is added, delete and separate options are now set to none by default.
Version 2.0(1) | 2018-07-16
NEW: Separate Document action: The Separate Document action is renamed to Separate / Page Processing and now includes additional page level processing options:
NEW: Delete Separator: Allows to delete all pages detected as separator. Only “real” separators are deleted. That means if the first page of a set is not detected as a separator according to the separator rules but only is a separator just because it is the first page of the set, it is not deleted. This situation happens when scanner operators don’t put as separator page on top of the set because the first page is a document by default. Documents inside the set will have separators and those will be deleted.
– Delete “if value of field…” or conditional deletion: allows to delete a page based on the content of a field.
– The “Separate every page” is now “Separate every n pages” where n is an integer. By default it is 1 but can be set to any other value like every 2 or 3 pages…
Version 2.0(0) | 2018-07-10
NEW: Export to Folder: If file exists, Append or Prepend new pages to the existing PDF. Exception flow if the file is locked (typically when the to be updated PDF is open in a PDF viewer).
Exceptions can be handled in two ways:
1) The file name contains a “file sequence number” variable. If the file is locked, a new version is created using the file sequence number containing the pages of the locked PDF + the new PDF. The File locked condition applies and an email export can be used to warn the user about the lock issue and the creation of a second version.
2) The file name does not contain a “file sequence number” variable. If the file is locked, nothing happens, the File locked condition applies and an email export can be used to warn the user about the lock issue, the file that could not be appended or prepended can be attached to that email.
ENHANCEMENT: More logically grouped Setup variables menus in all windows where variables can be picked from a Setup menu.