020 MetaTool Document Separation
Setting up keyword document separation
Kofax Express includes a very performant Separation feature. It supports 12 bar code types, blank separator sheets and 3 types of patch codes (Patch II, III and T). However, there are cases when these methods are not an option. For example, when there is no free space on the document for the bar code label or when you want to minimize the preparation of the documents and want to avoid using separator sheets.
MetaTool also supports additional patch code types for a total of 6 supported patch code types (Patch II, III, T, IV, V and VI) and also is more forgiving related to out of specification bar codes (very small quiet zones and missing leading and trailing * in barcode 39 for example).
But most importantly, with the MetaTool Document Separation feature, you can separate documents based on unique words on any page of a document using its very fast OCR engine. You can also use it to delete pages based on unique keywords you find on certain pages.
As an example we will use the CB MetaTool Keyword Doc Sep job. This job is automatically installed when you install CaptureBites MetaTool.
For those who prefer, there is also a video guide available.
01 Document Separation – Property Inspection Reports Case Study
Each inspection report has a different number of pages depending on the size and the state of the property. This can vary between 5 to 30 pages. You can split these documents by the first page or last page.
On each first page of the report documents, there are several unique words. For example, the words “WOOD”, “INSPECTION” and “REPORT” in the title on top of the page.






02 Document Separation – Setup
Document Separation rules are defined in the MetaTool Separation tab.
01 – No processing: if you don’t want your document to be separated or if there’s no need to delete any of its pages, enable this option.
02 – Delete page: when enabled, an index field can be used to identify which pages need to be deleted from your document.

When the selected index field has content (a value), the page will be deleted.
To generate a value in the index field, you make use of rules. These rules are identical to the extraction rules. Refer to the extraction help guides for a detailed explanation of each rule type. Typically, you make use of an Advanced OCR rule to extract a text block and use a Find Word rule to extract specific words from that text block. If any of the defined words exist on a given page, the index field has content and and the page will be tagged to be deleted. If none of the words exist in the text block on a given page, the index field stays empty and the page will not be deleted.
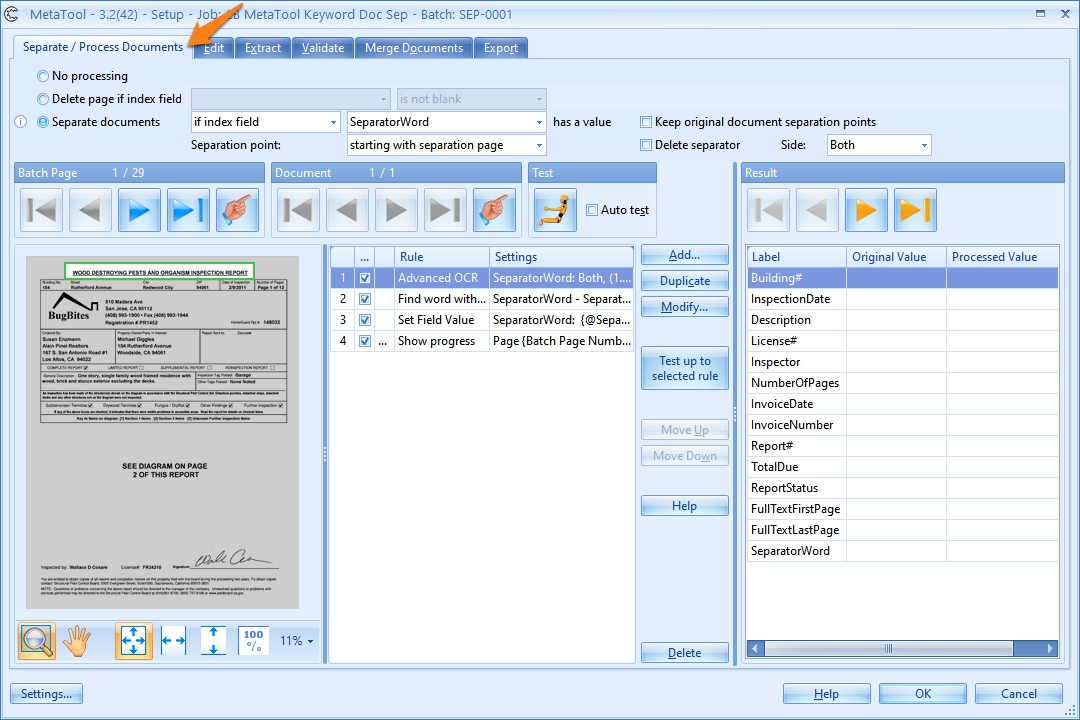
03 – Separate documents: when enabled, an index field can be used to identify the document separation points.

When the selected index field has content (a value), the page is recognized as a separator.
To generate a value in the index field, you make use of rules. These rules are identical to the extraction rules. Refer to the extraction help guides for a detailed explanation of each rule type. Typically, you make use of an Advanced OCR rule to extract a text block and use a Find Word rule to extract specific words from that text block. If any of the defined words exist on a given page, the index field has content and a separation point is created. If none of the words exist in the text block on a given page, the index field stays empty and the page is attached to the last document and is not considered as a separator point.
You can also separate documents for every page in case each page is a document:

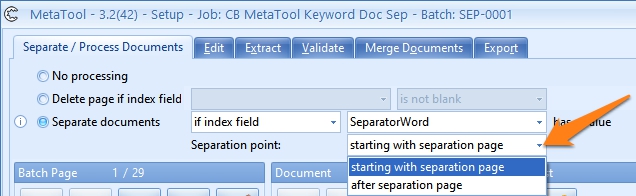
04 – Separation point: Use this option to set the separation point of the documents. When the unique separation keywords are located on the first page, the separation point would be set to starting with separation page. If they are located on the last page, the separation point would be set to after separation page.
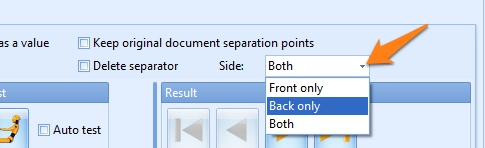
05 – Delete separator: Enable this option to delete the separation page. If it’s a double-sided page, you can choose to delete the front, the back or both sides. Make sure that Kofax Express is set to Both Sides in the Scan Settings tab if you delete back sides or both sides. If you import documents with FolderScan or AutoBites, you typically set One Side in the Kofax Express Scan Settings tab.
Removing the separator, can be useful when the separation page doesn’t contain any meaningful information and doesn’t need to be exported with the rest of the document. For example, patch code or bar code separator sheets, blank sheets or title pages are often just a mechanism to trigger document separation but can de deleted once they have served their purpose.
06 – Keep original document separation points: Enable this option to combine Kofax Express and MetaTool’s Document Seperation. You can use this, when Kofax Express misses some separation points. Sometimes Kofax Express struggles with bar codes printed very close to the edge of a label or of the page. In that case you can combine Kofax Express bar code separation with MetaTool bar code separation which is more forgiving. Or MetaTool can be used to look for ORC keywords like in our use case as a fall back in case Kofax Express missed a bar code. In short, with this option enabled, MetaTool will add missing separation points using its own document separation methods.
03 Document Separation – Results
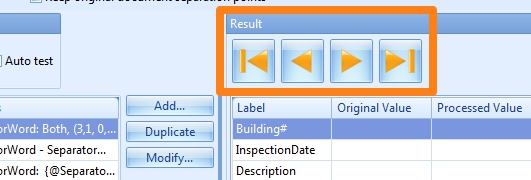
The dark yellow arrows are ideal to test the separation rules. They will apply the rules on each of the pages and will jump to the next page (or previous or last or first depending on the arrow) detected as a separator page.
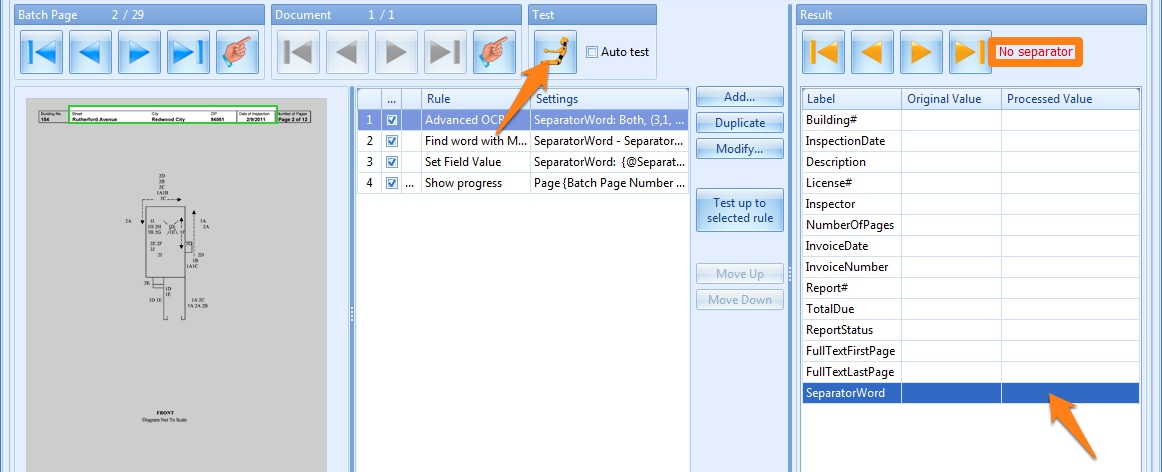
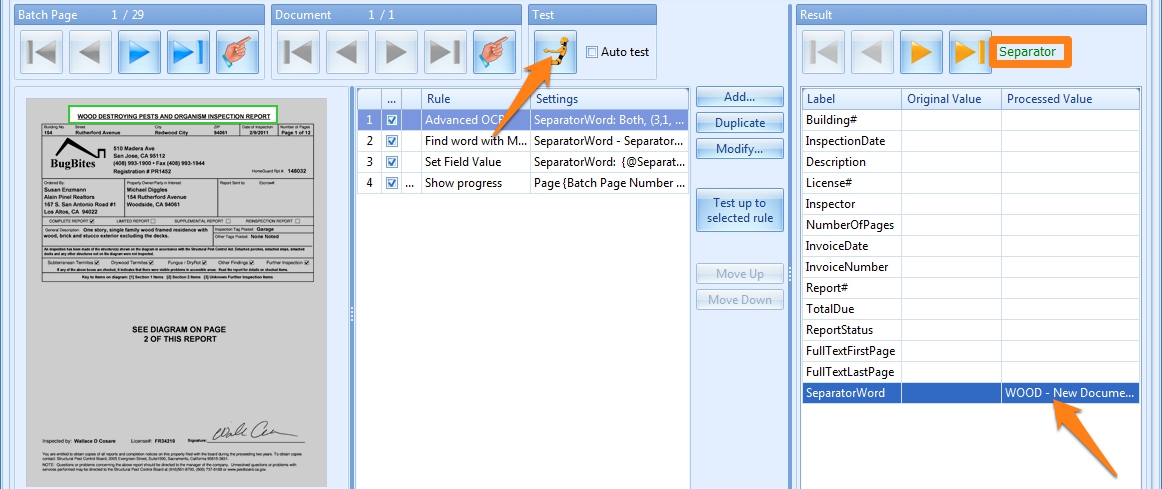
Result with separator, value for “WOOD” in index field “SeparatorWord”
If you want to see a how the complete setup is configured step by step, please have a look at the video guide below.