MetaServer > Help > Extract > Find Word Group with Mask / Words
120-290 MetaServer Extract – Find Word Group with Mask / Words
01 What is a Line, Word Group and Word?
A line of text is all the text on the same horizontal line. All the text in the green box below is located on the same line.
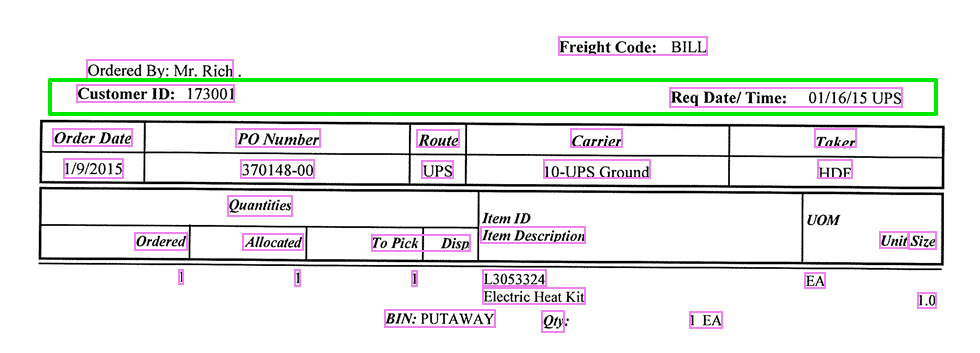
Word Groups are clusters of words separated by large spaces or TABs. As you can see in the example image, the word groups are marked in pink. The TABS are represented with a → character in MetaServer.
The line of text marked in green contains two word groups and is extracted by MetaServer as follows:
Customer ID: 173002→Req Date/ Time: 01/16/15 UPS
Words are separated with spaces. In our example, we marked some words in blue.
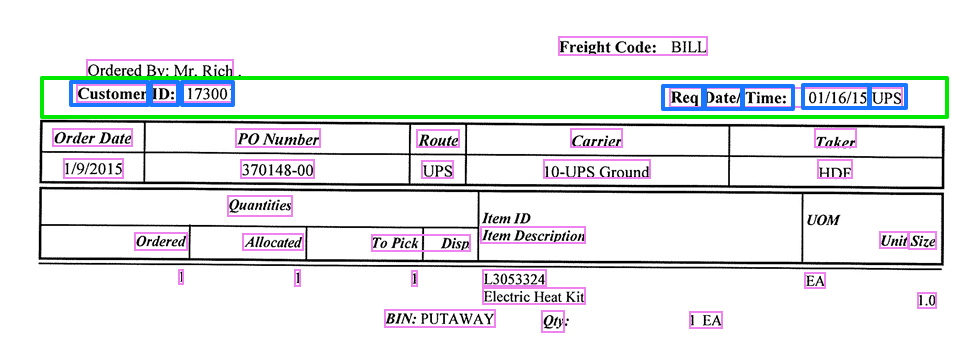
In conclusion, a line consists of 1 or more word groups, and a word group consists of 1 or more words.
MetaServer’s Find Word Group with Mask / Words rule makes it possible to find word groups, or word groups close to another word group. It is frequently combined with a Find Word with Mask / Words rule to extract a specific word from the found word group.
The Find Word Group with Mask / Words rule is very useful when you need to extract data from documents that don’t have a fixed format. The classic example is a vendor invoice. All invoices have an invoice date, invoice number, total amount etc. but the data and its keywords are located on a different place for each supplier.
An invoice also contains many amounts and dates and numbers that look like invoice numbers.
You can extract the correct amount by looking for amounts close to word groups like “Total Amount”, “Amount Due” and “To Pay”. Same with the Invoice Date and the Invoice Numbers
You typically define an Extract Text rule first to hold the full text of the document in an index field we call Text Block or Full Text. Next, you would define a Find Word Group with Mask / Words to filter the full text and only keep word groups containing the data you are interested in.
For example, to extract the invoice number from an invoice, you can search for keywords around the invoice number like: Invoice Number, Invoice Nr., Document Number, Invoice# etc. This would reduce the full text to word groups close to the defined keywords. Next, you extract the invoice number from these groups using a Find Word with Mask / Words rule.
In our example, we will make use of the “CB – SHIPPING” workflow. This workflow is automatically installed with CaptureBites MetaServer.
Find Word Group with Mask / Words rules are defined in a MetaServer Extract or Separate Document / Process Page action.
To add this rule, press the Add button and select Find –> Word Group –> with Mask / Words.
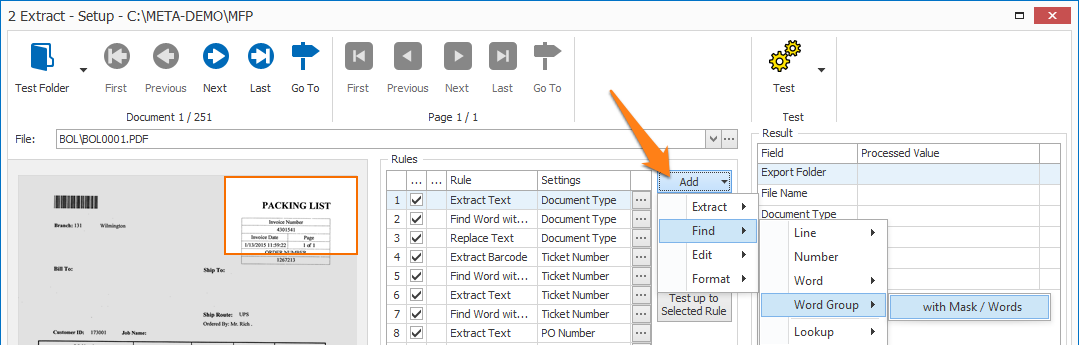
03 Find Word Group with Mask / Words – Setup
We want to extract the PO number from the image samples below. As you can see, the PO number is located beneath the label “PO Number”.



TIP: The thumbnail on the right will follow you, so you can easily refer to the Setup window. Click on the thumbnail to zoom in.
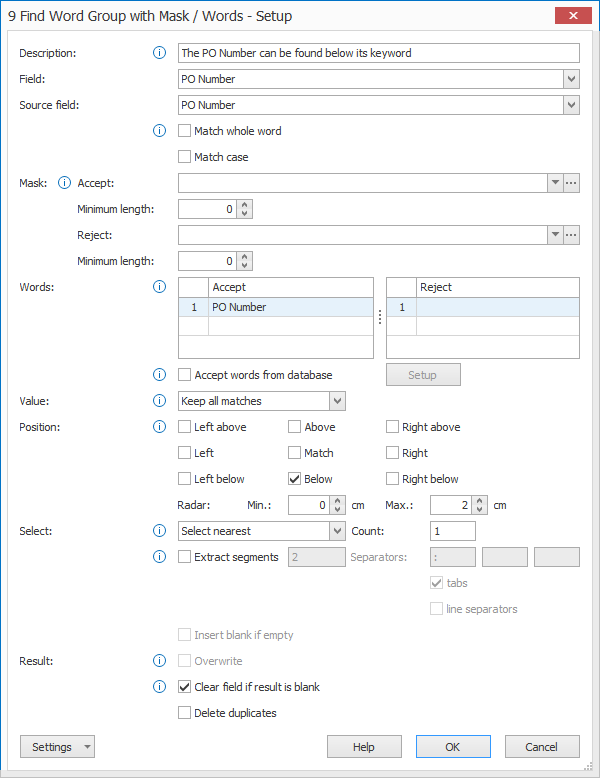
First, add a description to your rule. Then, select a field to hold the extracted data. In this case, we select the field “PO Number”.
01 – Source field: press the drop-down arrow to select the source field. This is the field containing the text you want to parse to find word groups containing the required data.
1) Match whole word: only returns word groups exactly matching the defined mask or word(s). When disabled, it will also return word groups containing the accepted word or mask. For example: with “Match whole word” disabled and when searching for “apple”, it will also return word groups containing “pineapple”.
2) Match case: enable this option to make the search Case Sensitive. If you search for “PO Number”, for example, it will only return word groups with that word in the exact same case. Disable the option to also find “po number”, “PO NUMBER”, “PO number” etc.
Masks are used to search for a word group containing a word with a format also known as a regular expression. However, you don’t need to use complex regular expressions, MetaServer uses an easy to use formatting pick list and you can construct your mask by selecting the elements you need.
Example: you want to find the date which is right below the telephone number:
– Assume telephone numbers always look like 859-232-0000.
– You would look for a word group containing a mask: { 9, 3 }-{ 9, 3 }-{ 9, 5 } with a minimum length of 12.
This would find the word group containing a telephone number. Then with the Position settings, you define that you want to select the word group below the found telephone number. Next, with a Find Word rule, you would select the date in that word group.
The Reject mask is used to skip lines containing words with the defined Reject mask.
For example, if you want to skip all word groups containing dates between the years 1900 and 1999, you could define a reject mask like 19{ 9, 2 }. See below for details about the mask syntax and how to define a mask.
TIP: when you have both Accept and Reject masks defined in a single rule, all the word groups containing words matching the reject mask are eliminated first. Then, the remaining word groups are used to only keep the word groups containing words matching the accept mask.
01 – Accept / Reject masks: here you define the masks. Word groups containing a word matching the Reject mask will be eliminated, word groups containing words matching the Accept mask will be kept. Both masks use the same setup method.
By pressing the drop-down arrow, you can select different format types to compose your mask. You can even add a field to your mask, so it can change dynamically based on that field value.
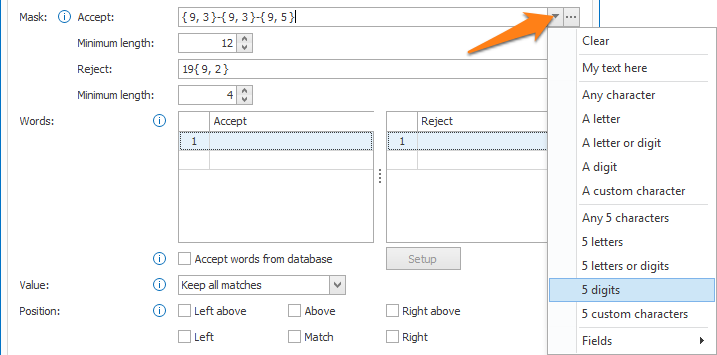
1) Clear: clears the mask.
2) My text here: an example text. You can overwrite it with your own text. Use it if your masks consist of fixed characters. It’s also possible to type fixed text directly in the mask’s input box.
3) Any character: shown as { ? }, any character is allowed.
4) A letter: shown as { A }, any letter is allowed, both upper and lower case. If you want to only accept a specific case, you can use a custom character.
5) A letter or digit: shown as { X }, any letter or single digit is allowed. If you also want to allow periods, hyphens, commas, etc., you need to use the { ? } “Any character” type.
6) A digit: shown as { 9 }, any single digit is allowed.
7) A custom character: shown as { C }, only allows a list of defined characters. You can define these in the Custom Character Setup. Press the “…” button next to the Accept or Reject Mask to set up your custom characters.

The Custom Character Setup window opens…
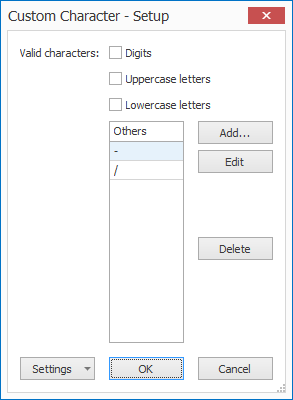
Above custom character definition only allows a “-” or “/” for every C element in your mask.
1) Valid characters: you can choose if the custom character also allows uppercase letters, lowercase letters or digits.
2) Others: Here you can add, delete or modify specific custom characters. In the example above, a custom character can only be a “–” or “/”.
8) Any 5 … : the number 5 is just an example, replace the 5 with the number of characters you want.
For example: { ?, 6 } means any 6 characters, { A, 2 } means 2 letters, { X, 5 } means 5 letters or digits, etc..
02 – Minimum length: If you only want to read a part of the mask, set the minimum length lower than the total length of the mask.
To explain how the Minimum length setting works, consider below settings:

Examples:
AB/15687945-2:
OK, because the number of characters is greater or equal than the defined minimum of 13 and the value contains 2 letters, a custom character (“/“ in this case), 8 digits, a dash and a single digit.
AB/157945-2:
NOT OK, because the number of characters is smaller than the defined minimum length of 13.
AB/156870945-02:
NOT OK, because longer (15 digits) than the total length of the defined mask, if you want to accept words containing more digits, you would need to disable “Match whole word”.
4B/15687945-2:
NOT OK, because it contains another type of character than a letter in the first 2 characters and therefore does not comply with the defined mask.
Here you can specify words that should or shouldn’t be included in the word group.
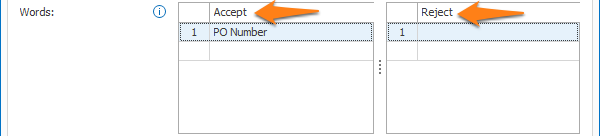
1) Accept: return word groups consisting one of these words.
2) Reject: when one of these words appear in a word group, it will be rejected. Even when it has also found an Accept word in the same word group. Reject words win from Accept words.
Note: Spaces also count as characters.
With the “Accept words from database” option, you can maintain a list of Accept Words outside MetaServer using an external database.
Enable the “Accept words from database” option and press the Setup button.

The Accept words from database Setup window opens…
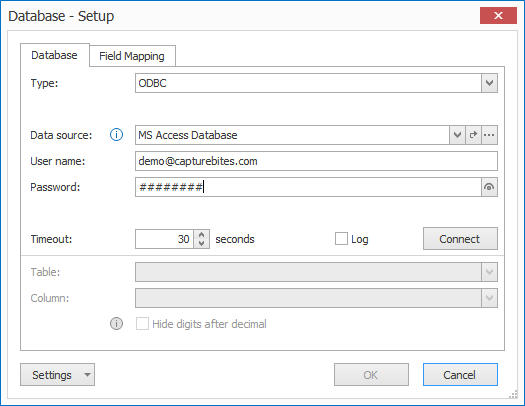
Here you can select the database table and column containing the Accept Words. Any changes you make in the selected database table are automatically applied.
01 – Hide digits after decimal: in Oracle databases through ODBC, NUMBER(14) are integers but they are reported as DECIMAL. To avoid that, for example, an order number like 123456 is returned as 123456.00, you can enable this “Hide digits after decimal” option.
This can also be useful if ID numbers are stored as a NUMERIC or DECIMAL data type in MsSQL.
NOTE: thousand separators are never displayed in looked up decimal values, regardless whether the option is enabled or not.
This only applies to the lookup field, not the mapped fields.
Here you select your database type:
ODBC
ODBC is a standard to connect to a wide range of databases. Configuring an ODBC data source is straightforward. For detailed instructions on how to define an ODBC data source, please have a look at this guide.
IMPORTANT: It is not possible to connect to a “single-access” database type (e.g. Excel). This technical limitation applies for both database lookup during extraction and validation. This limitation does not apply for exporting to a database.
This is an overview of the ODBC settings:
1) Data source: select the data source you want to use. An ODBC data source needs to be defined first using the ODBC Data Source Administrator tool in Windows. To find step by step instructions how to define an ODBC Data Source in Windows, have a look here.
Select data source from field: you can use this option to switch databases dynamically using a field value.
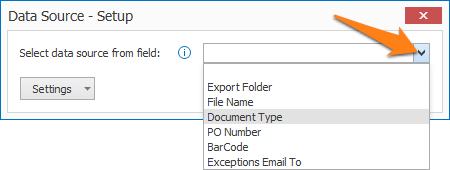
To access this setup window, press the “…” button next to Data Source. You can select the field containing your database name by pressing the drop-down arrow.
Be aware that when you use this feature, all possible databases that can be loaded, must share the same table name and schema.
2) User name & Password: some databases require to login. If so, enter the user name and password in these fields.
3) Timeout: when the database does not respond in the specified time, the action will fail.
Log: enable this option to create a log file each time the database is called. This option is typically used during testing.
On the client side, you can find the information in the following folder:
C:\ProgramData\CaptureBites\Programs\Admin\Data\Log
On the server side, you can find the information in the following folder:
C:\ProgramData\CaptureBites\Programs\MetaServer\Data\Log
SQL Server
When you use a direct connection, it’s not required to set up an ODBC data source. Because the communication with the SQL server is direct, searching and updating SQL tables is more efficient.
NOTE: If you change the connection type from ODBC or a MetaServer Database to Direct SQL and you connect to the same table with identical field names, the mappings are preserved.
MetaServer
A MetaServer database is a shared CSV database. It doesn’t require any ODBC sources on any of the clients and is very easy to deploy. The MetaServer DB settings are very similar to the MS-SQL and ODBC settings.
For help on how to create a MetaServer database, you can refer to this guide.
To create a MetaServer database, you simply create or copy a CSV file in:
C:\ProgramData\CaptureBites\Programs\MetaServer\Data\DB
The CSV file needs to comply to the following characteristics:
1) The first line defines the column names
2) The following lines are data records
3) Fields are separated by “,” (comma) or “;” (semi colon)
Example of a basic CSV:
VENDOR_NAME,VENDOR_ID
ARROW ELECTRONICS,9492785400
Cisco WebEx LLC,8754441234
Dell,9598741234
Evernote Corporation,6584568754
K Software,8595140754
PremiumSoft CyberTech Ltd.,85224983422
Vivify Scrum,5554872315
WPForms LLC,8787775487
The “,” delimiter can also be a “;” delimiter.
Here is the example CSV again as seen in a CSV Viewer:
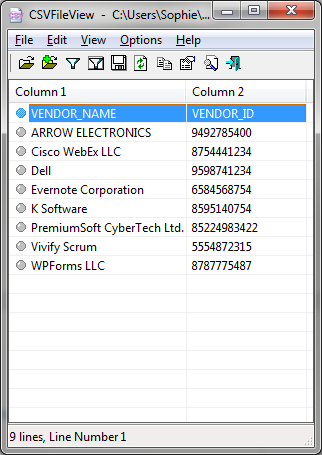
NOTE: the ; (semi-colon) delimiter is often used in Europe because the comma is commonly used as a decimal point in European countries.
If you use a comma delimited CSV and you have values containing a comma, you need to put the value between double quotes. A value like 22500, Broadway would need to be quoted like “22500, Broadway” to avoid the comma in the street to be interpreted as a field separator.
01 – Value: You can specify which word groups you want to keep. There are 3 options:
1) Keep all matches: this will return all word groups containing the defined Accept Mask or Accept Words and not containing the defined Reject Mask or Reject Word(s).
2) Keep first match: this will return the first word group containing the defined Accept Mask or Accept Words and not containing the defined Reject Mask Reject Word(s).
3) Keep last match: this will return the last word group containing the defined Accept Mask or Accept Words and not containing the defined Reject Mask or Reject Word(s).
02 – Position: when selecting “Match” as the position, only the word groups that meet the requirements of the Accept and Reject settings will be kept. But you can also keep word groups surrounding that match.

For example, in our case:
We need to look for the number below the label “PO Number”, so we define “PO Number” as our Accept Word and select “Below” as our position to find the number below the match.
The Radar sets the distance how far from the match you want to look for word groups. This is expressed in a minimum and maximum radar distance using the metric system or inches, depending on your regional settings.
For example, you have a list with 6 rows extracted from a document:
| Type | Make/Model | MSRP |
| HEV | Hyundai Santa Fe Hybrid/Hybrid Blue | $33,650 |
| HEV | Hyundai Tucson Hybrid/Hybrid Blue | $30,900 |
| HEV | Jaguar F-PACE P340/P400 MHEV | $64,800 |
| HEV | Jeep Wrangler 4dr 4×4 | $34,045 |
Assume you want to extract the price column.
You could use the column with the word “HEV” as the anchor column and measure the distance between the end of the word “HEV” and before the prices. This would be your Minimum Radar Distance.
Then, you measure the distance between “HEV” and after the prices. That would be your Maximum Radar Distance.
MetaServer determines the position of a word group relative to the match by looking at the centers of the bounding rectangles, as shown in the graph below.
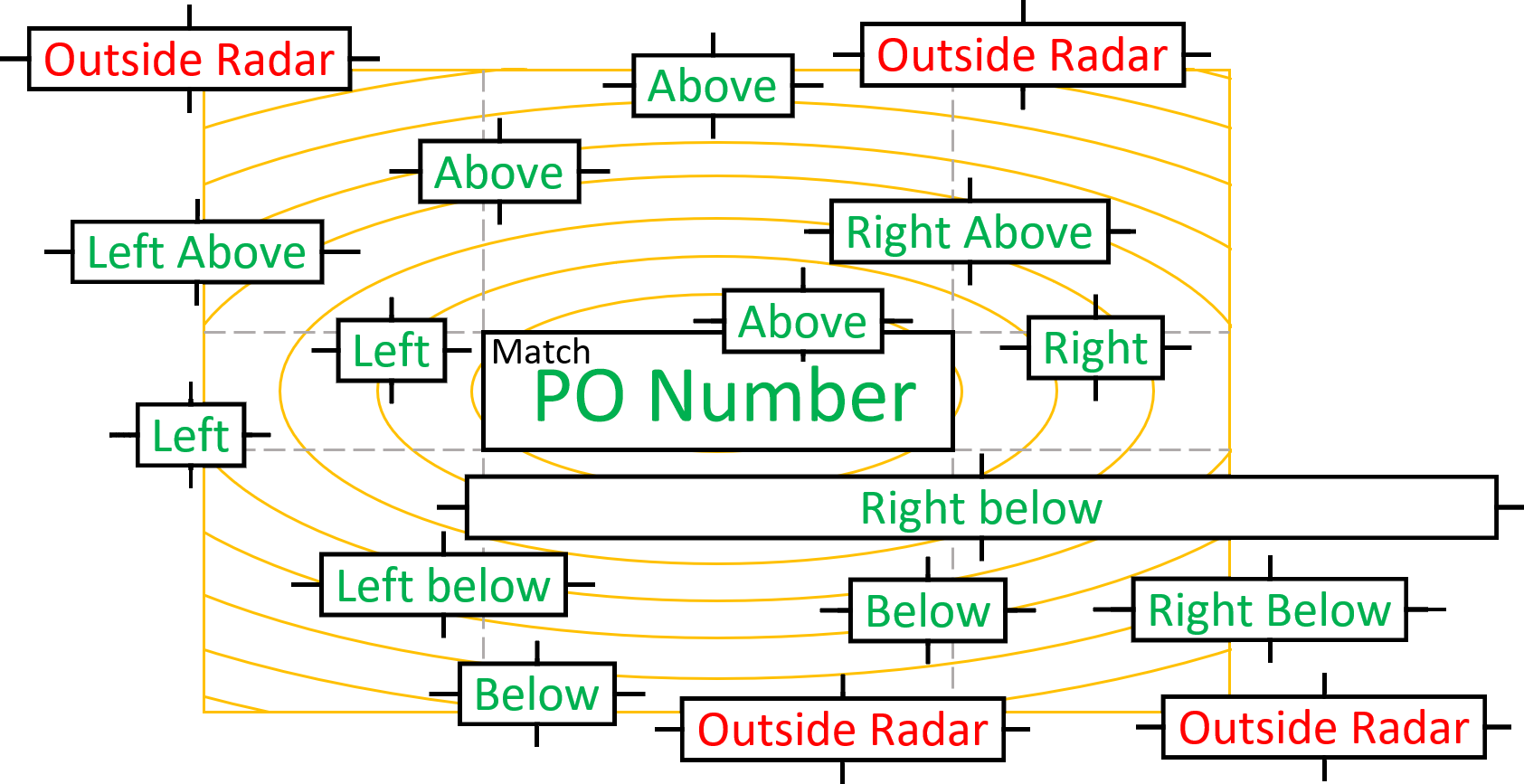
03 – Select: you can specify which word groups are to be found based on the following 3 options:

1) Select all: all word groups inside the radar and in the defined position(s) are kept.
2) Select nearest: the word group nearest to the match is kept.
3) Select furthest: the word group furthest from the match is kept.
4) Count: this sets the number of word groups you want to select. For example, “Select Nearest” with “Count” 2 will select the 2 nearest word groups. The default is 1, which only keeps one word group.
04 – Extract segments: enable this option if you want to extract one or more segments from a word group with delimited values.
For example, consider this word group:
“Address: P. Sherman, 42 Wallaby Way, Sydney 1001”
You define the separators as a “:” and “,” to extract the following segments:
Segment 1 = Address
Segment 2 = P. Sherman
Segment 3 = 42 Wallaby Way
Segment 4 = Sydney 1001
The leading space before “P. Sherman” is automatically removed. You can also enter negative values in the segment selection box. -1 indicates the last value, -2 indicates the value before the last value, etc.
If we use those segments in our example:
Segment -1= Sydney 1001
Segment -2 = 42 Wallaby Way
TIP: word group separators represented by → (TAB) are always considered as a delimiter.
For example:
“Name: Gerald→Species: Seal”
If we define the separators as a “:”, we extract the following segments:
Segment 1 = Name
Segment 2 = Gerald
Segment 3 = Species
Segment 4 = Seal
01 – Insert blank if empty: enable this option if you need to extract columns without a value.
For example, assume you want to extract the price column and preserve the empty lines, if any are present.
| Type | Make/Model | MSRP |
| HEV | Hyundai Santa Fe Hybrid/Hybrid Blue | $33,650 |
| HEV | Hyundai Sonata Hybrid/Hybrid Blue | |
| HEV | Hyundai Tucson Hybrid/Hybrid Blue | $30,900 |
| HEV | Jaguar F-PACE P340/P400 MHEV | $64,800 |
| HEV | Jeep Wagoneer 4WD | |
| HEV | Jeep Wrangler 4dr 4×4 | $34,045 |
You set the Minimum Radar Distance to the distance between “HEV” and before the prices, and you set the Maximum Radar Distance to the distance between “HEV” and after the prices.
Finally, you enable the Insert blank if empty option to insert an empty line for cars without a price.
The result would only contain the prices and blank lines where there was no price resulting in exactly 6 lines.
$33,650
$30,900
$64,800
$34,045
You can use the same method to extract the “Make” and “Model”, which will also result in 6 lines:
Hyundai Santa Fe Hybrid/Hybrid Blue
Hyundai Sonata Hybrid/Hybrid Blue
Hyundai Tucson Hybrid/Hybrid Blue
Jaguar F-PACE P340/P400 MHEV
Jeep Wagoneer 4WD
Jeep Wrangler 4dr 4×4
Fields with the same number of lines can be merged with a Set Field Value rule.
With this technique, you can extract the line items column by column, apply Replace Text rules on individual columns, and then merge them in a CSV format. After that, you can validate the CSV value with a Validate CSV rule.
02 – Overwrite: if enabled, the result will overwrite the previous field value. Otherwise, the result will be appended to the value that is already in the field.
03 – Clear field if result is blank: if the result is blank, any values already in the selected field are cleared.
04 – Delete duplicates: this will delete all duplicate matches and the result will only return unique values.
TIP: you can copy the current settings and paste them in another setup window of the same type. Do this by pressing the Settings button in the bottom left of the Setup window and by selecting Copy. Then open another setup window of the same type and select Paste.

