MetaTool > Help > Validation > Multi-line text
080-180 MetaTool Validation – Multi-line text
With the MetaTool Multi-line Validation rule, you can validate if an automatically extracted Multi-line text value is correct and if it is not, define settings to make the user manually enter a correct value. Manual entry can be semi-automated by using Rubber band or Single click OCR.
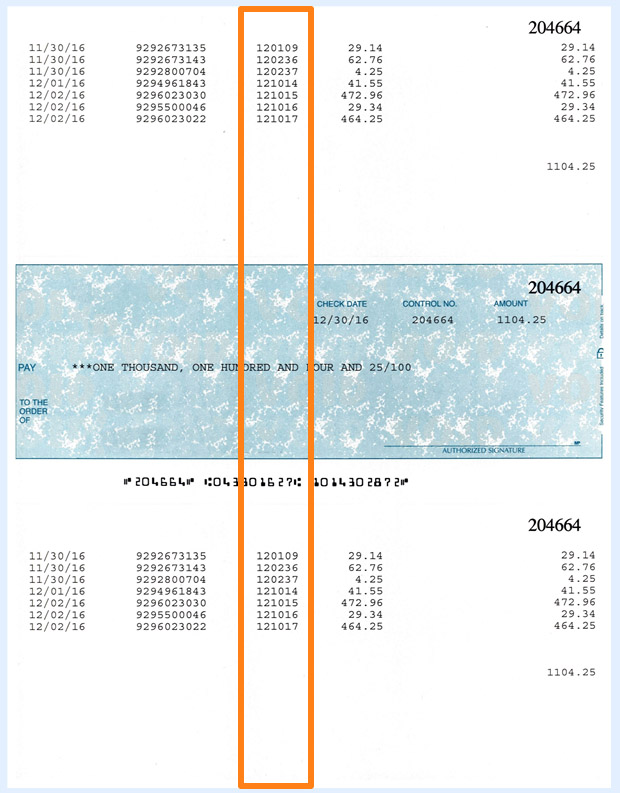
In our basic example, we need to extract and validate the invoice numbers on checks. Because there are multiple invoice numbers on each check, we need to use a Multi-line text Validation rule.
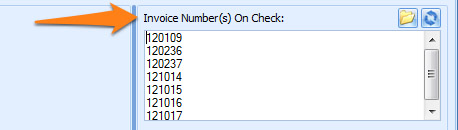
We already defined some extraction rules to extract the invoice numbers from the zone marked in orange below. The result is an index field with multiple invoice numbers. One on each line. We want to validate these invoice numbers and for each invoice number check if a TIF file exists named after the invoice number.
01 Multi-line – Add Rule
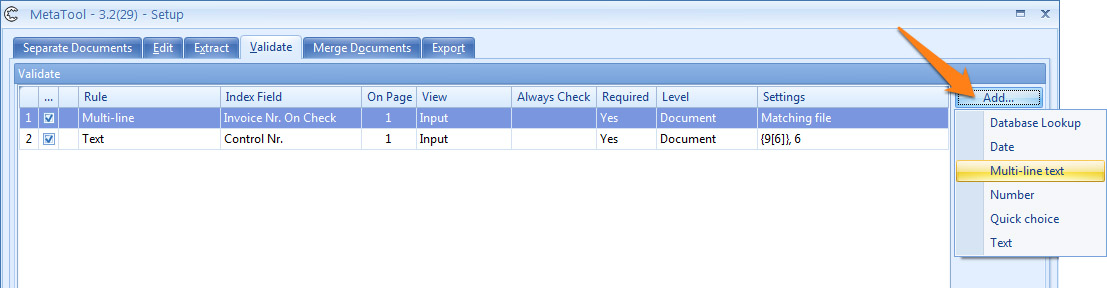
Multi-line Validation is defined in the MetaTool Validation tab.
Press the Add button and select Multi-line to add the validation rule.
The Muti-line Setup window opens.
02 Multi-line – Setup
TIP: The thumbnail on the right will follow you, so you can easily refer to the Setup window. Click on the thumbnail to make the image larger.
01 - Navigation Tool Bar:
1) Document buttons: use the green buttons to navigate through the documents in the current batch.
2) Page buttons: use the blue buttons to page through the current document if it has more than one page.
3) Zone menu: use the Zone menu to select the highlight zone during validation. This is the portion of the image that will be highlighted during validation when the user selects the index field. It is used to draw the attention to the zone on the page where the data is expected.

Lasso

Full Page

Bottom Half

Top Half
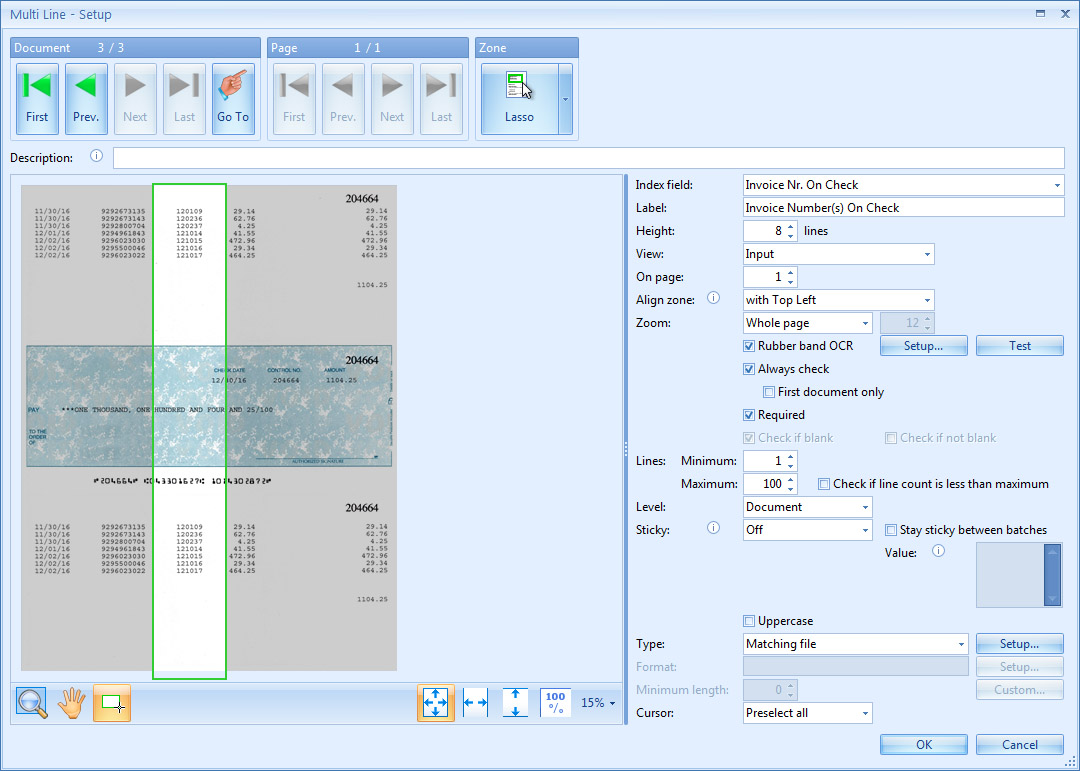
02 – Index field: select the index field “Invoice Nr. On Check” that holds the Multi-line text value you want to validate. Optionally, we enter a description.
In this setup, you have the following requirements for the Invoice Nr. On Check:
- The Invoice Nr. On Check is Required, the validation window will pop up if it’s blank and the validation user is required to give a value to progress.
- When validating, you have the option to rubber band the text or enter it manually.
- Each Invoice Nr. On Check needs to match with the already existing files in the folder named after the Control Number of the check. Please refer to the Add Folder Edit rule for a more in-depth explanation.
03 - Label: here you enter the label that will appear above the input box during export in the Validation window. By default, this is the same as the selected index field name. But you can also enter something more meaningful. Like, in this example, add some hints about how to enter the data.
04 - View: there are 4 possible View options. Press the drop-down arrow to choose an option.
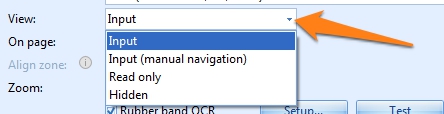
1) Input: the user can enter information in the index field. When he navigates in the field during validation, the page specified in the On page setting will be selected, the green selection in the viewer, as defined in the Zone menu, will be highlighted and the zoom setting defined in the Zoom option will be applied.
In other words, input fields automatically draw the attention to the place where the information is expected on the page.
2) Input (manual navigation): the user can enter information in the field when he navigates in the field. The displayed page, the image zoom and highlight will not change and will be whatever was last selected. This is useful when the expected location of the information on the documents is unknown and can be potentially anywhere on any of the pages on the document.
3) Read only: the field value cannot be changed. This is typically used for automatically extracted or looked up data that should not be modified by the user. The data is for display only.
4) Hidden: this is typically used for automatically extracted or looked up data that should not be viewed or modified by the user.
05 - On Page: sometimes the information for the index field is on another page than page 1. With this option, you can exactly define on which page the data is expected. When the user selects the field during validation, the viewer will automatically display the correct page.
You can also enter negative page numbers. Page -1 is the last page, -2 is the page before the last page, etc.
06 - Align zone: when you select a highlight zone in the viewer with the Lasso tool in the Zone menu, by default it is aligned with the Top Left of the page.
For information located in the bottom of the page, like a Total Amount on an invoice, it is better to align the highlight zone with the Bottom Right of the page. Especially when the format of the documents switches from landscape to portrait like in below example.

Bottom right alignment of a highlight zone on a portrait oriented image

Bottom right alignment of a highlight zone on a landscape oriented image
07 - Zoom: here you can choose the zoom option that should be automatically applied when the user navigates in the selected index field. The automatic zooming is only active when the selected View option is set to Input. Automatic zooming is disabled when the selected View mode is set to Input (manual navigation), Read-Only or Hidden. Press the drop-down arrow to choose an option.
1) Whole page, Page width and Page height: these options are self-explanatory.
2) Zone: the viewer will automatically zoom to the zone defined in the Zone menu.
3) Font size: the viewer will show text in the font size specified. Font size 12 is standard and shows text in real size.

03 Rubber Band OCR
Enable this option if you want to activate the rubber band OCR tool when the user navigates in the selected index field. With the rubber band OCR tool, the user can draw a rectangle around a part of the text to OCR it and fill it out in the index field.
TIP: The thumbnail on the right will follow you, so you can easily refer to the Setup window. Click on the thumbnail to make the image larger.
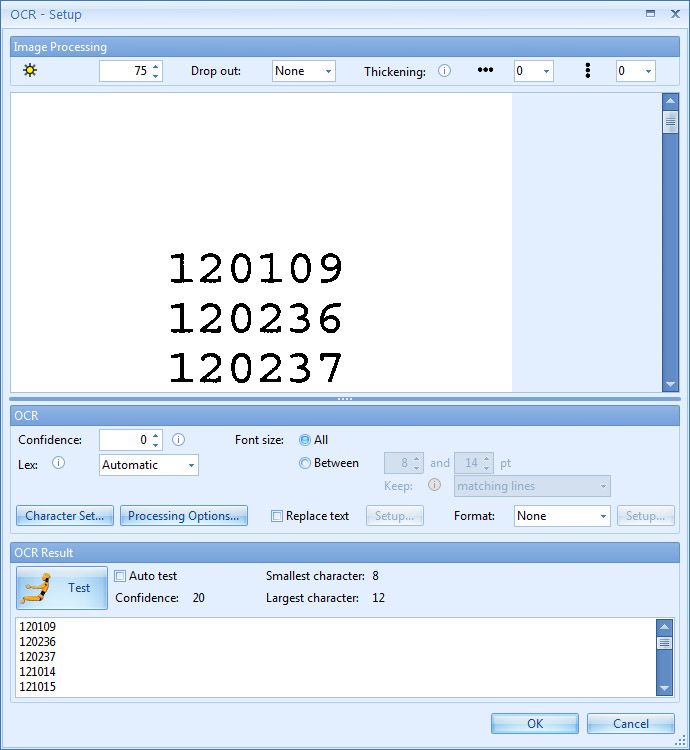
Here you set the OCR settings that will be applied when the validation user draws a selection around a zone on the page for a particular index field. In other words, the settings should focus on the text that is potentially contained in the selected zone. If, for example, the index field is a zip code, you know that the user will draw a zone around a block of text only containing digits.
01 - Brightness: (represented by the small sun symbol) By increasing the brightness value, you make the scanned image brighter. Decreasing the value makes it darker. This can be very useful when working with documents that contain faint text or a lot of noise or have a dark background as seen in the example below.
To test your settings, press the Test button (button with the yellow test dummy icon). Because we do not know the zone that the user will select during validation, the test will be applied on the zone defined in the Zone menu.
02 - Drop out: when working with forms with lines and labels in red, green or blue, we can filter these by using the drop out setting.

Drop out: None

Drop out: Red
03 - Thickening: when extracting dot matrix printed text, you can use this option to make the text bolder in the selected direction(s). The thickening removes the gaps between the dots and makes each character solid. This improves the recognition considerably.
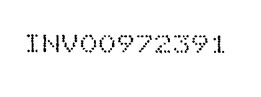
Thickening value: 0
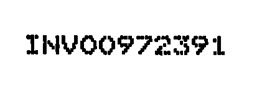
Thickening value: 2 horizontal, 3 vertical
04 - Confidence Level: when set to 0 (default) extracted characters with a confidence level between 0 and 100 are allowed. In other words, nothing is rejected, even characters with a very low confidence level. Increase the value to reject characters with a low confidence. In combination with a strict validation Format, this can be useful to make sure that critical data is extracted correctly.
For example, when extracting an 8-digit account number that needs to be absolutely correct, set the confidence level to 95. Any character lower than 95 will be rejected resulting in an account number with less than 8 digits. If you set a validation Format to only accept 8 digits account numbers (format 9(8) min. length 8), the user will be forced to enter the questionable digits manually.
05 - Lex: Lex processing is to avoid confusion between look-a-like characters such as 0 and O, 1 and I, 8 and B. It is not language-dependent but uses surrounding characters to detect context. By enabling Lex, you can improve accuracy by interpreting each character in context of the characters around it. Do not enable Lex when working with zones with random character patterns (for example license plates or VIN numbers). When in doubt, select “On”.
06 - Font size: by default, only lines containing at least one character in the range of the specified font-sizes will be accepted.
Keep: you can work more precisely, if you select matching words, it will only accept words that contain characters in the range of the specified font-sizes.
If you select the character level option, then only characters in the range of the specified font-sizes will be retained.
Please refer to Advanced OCR for a visual example.
07 - Character set: use the character set, to exclude or include certain characters. This is useful to extract a value that, for example, only contains numbers or contains only a few special characters. This avoids confusion with other characters that never occur in such number. For example, if the zone only contains a numeric value, disable all letters to avoid confusion between 0 and O or 1 and I.
You enable or disable a character by simply clicking on it. You can also hold the left mouse button and drag over a range of characters to select or deselect them.
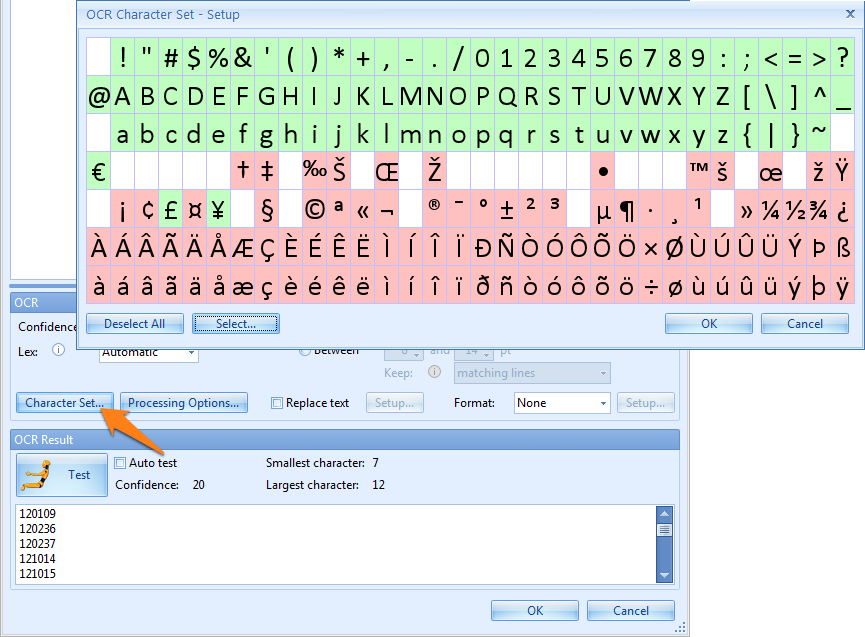
You can choose preselected character sets by first pressing Deselect All and then under the select button you can choose between digits, upper- and lowercase letters, a character set matching a specific language etc.
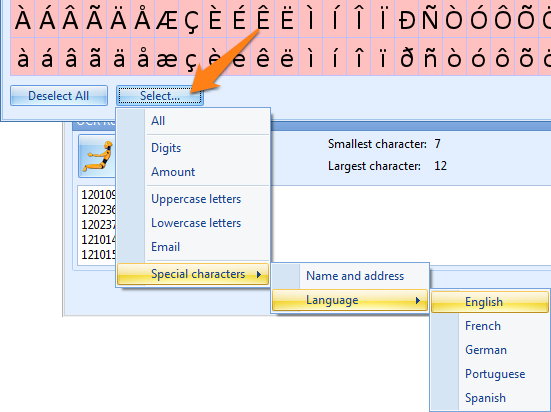
TIP: Do not use the character set to exclude elements from text.
For example, if you want to read 123/456/789 and reject the / symbols, you may be tempted to exclude the / from the character set. However, if you do so, the / symbol will most likely be recognized as a 1 which makes things actually worse. Better is to leave the / symbol in the set and remove it with the “Replace text” option (replace "/" with nothing).
08 - Processing Options: there are 3 categories of processing options:
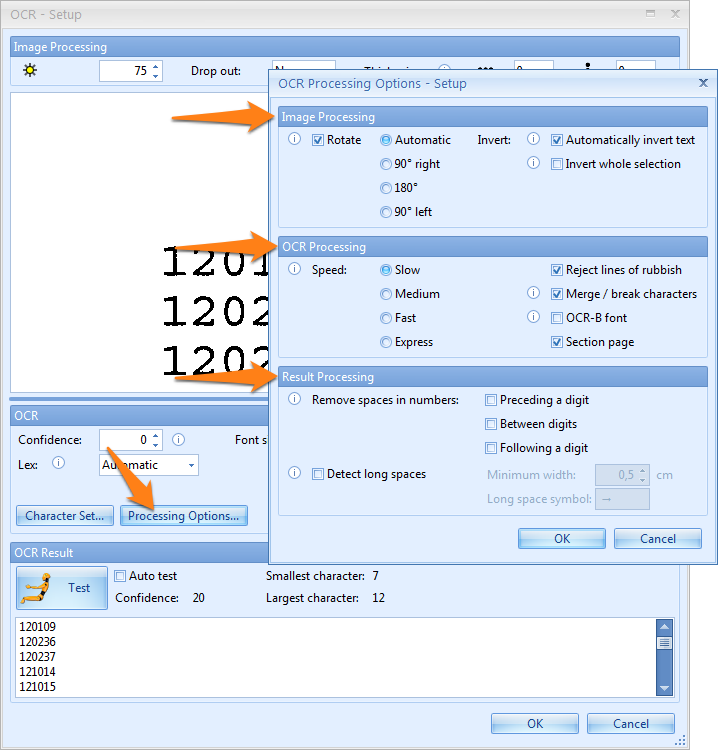
1) Image Processing: here you can adjust the rotation and inversion settings:
Rotate: the selection will be rotated as specified before OCR processing.
Invert: there are 2 options:
1) Automatically invert text: automatically detects inverted text object in the selection (white text on dark background) and inverts it before sending the selection to the OCR engine.
2) Invert whole selection: always invert the whole selection.
2) OCR Processing: here you can adjust the processing speed and quality of the OCR engine:
Speed: the speed option indicates how exhaustive the OCR progress should be looking for improvements. There is a small loss in accuracy from slower to faster speed options.
Reject lines of rubbish: this detects random characters with a low confidence level caused by noise in the image. Enable this option to automatically delete lines of rubbish.
Merge/break characters: enable this option when characters stick together. This technology uses font size detection to determine the break points.
OCR-B font: only enable it when the text you want to extract is created with the OCR-B font. OCR-B is a sans-serif font with a fixed pitch. That means that all characters take the same space. For example, the letter i takes the same space as the letter W.

OCR-B font
Section page: experiment with this setting when there are different font-sizes on the same line. Sometimes sectioning may drop results when different font sizes occur on the same line.
3) Result Processing: use this for the final filtering of the OCR result:
Remove spaces in numbers: the OCR process sometimes generates redundant spaces in numeric data. You can reject spaces preceding a digit, between digits or following a digit.
Detect long spaces: replaces long spaces with a specified symbol in the OCR result. A long space is a space between two words longer or equal to the specified length. By default, long spaces are represented by the → symbol and by default the minimum length of a long space is 0,5 cm or 1/5th of an inch.
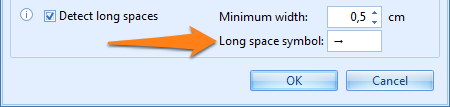
Handling long spaces can be important to make Single click OCR work correctly when used in combination with the option “Remove spaces in numbers”.
Imagine data looking like this:
Invoice Nr. Customer Nr.
1 2 3 4 5 6 9 9 9 9
Because of the excessive spacing between the digits, we want to enable “Remove spaces in numbers”. However, if we would apply Single click OCR on the invoice number, it would return 1234569999 because the space between the last 6 of the invoice number and the first 9 of the Customer Nr. would also be removed.
However, by replacing long spaces with →, Single click OCR on the Invoice Nr. would return 123456 correctly.
04 Rubber Band OCR – Replace text Setup
Enable this option if you want to Replace text in the rubber band OCR result. With this tool, you can clean up text, convert alphabetic months to numeric months, or correct OCR-mistakes in the rubber band OCR result to get correct and consistent output.
Our multi-line use case has no need for the Replace text option, so we will use another example where we need to replace the alphabetic months in numeric ones.
Press the Setup button next to this option to access additional options.
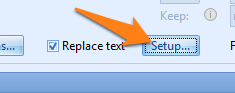
The Replace text Setup window opens.
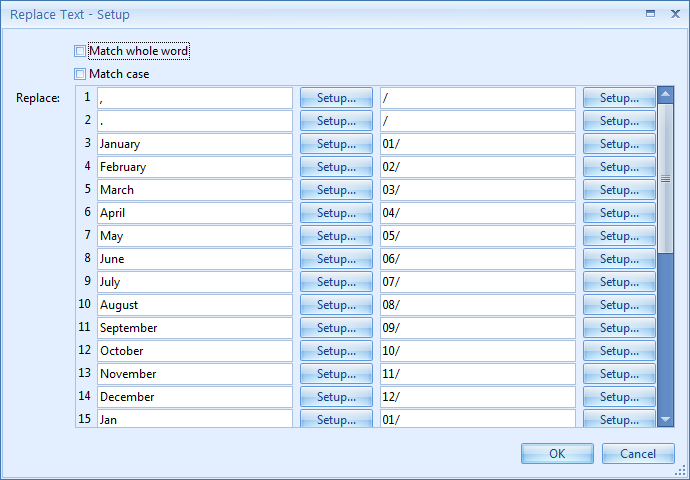
The Replace text option in action. The alphabetic month is automatically converted to numeric format:
01 - Match whole word: only replaces text exactly matching the defined word(s). When disabled, it will also replace the specified text if it’s a part of a word.
For example, when Match whole word is disabled and when replacing “apple” with “orange”, it would also replace it in words containing “apple”, like “pineapple” would become “pineorange”. If the option is enabled, the rule will only replace the word “apple” if it is a whole word and ignore words like “pineapple”.
02 - Match case: only replaces text that exactly matches the defined word(s) case. When disabled, it will replace the specified word(s), regardless the case.
For example, when enabled and when replacing the word “January, it would only replace the word “January” and ignore words like “january”, and “JANUARY”.
03 - Replace: here you enter the text you want the rule to replace. Enter the words you want to replace in the left column. In the right column, you enter the values that the words in the left column will be replaced with. You can define up to 30 words to be replaced.
In our case, we will replace the “,” and “.” characters to “/”, and the months in long and short alphabetic name format with their numeric format.
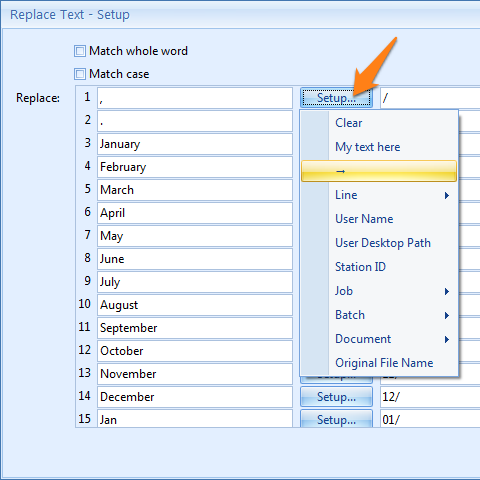
By pushing the Setup button, you can select different system and index values to compose your text. In our example, we just enter the months followed by a space in the left column and the corresponding numeric month value followed by a slash in the right column.
TIP: When there is an extra space between symbols or text that needs to be removed, include the space to be replaced in the left box. For example replace "January " (note the space at the end) with "01/".
Important: Please, be aware that the replacement of the defined words will occur in the sequence the words are entered in the replace rule.
For example, if you first replace “Jan” with “01/” and then “January” with “01/” the rule will not work correctly. Such rule would convert a date like “Jan 8” to “01/8” just fine. But a date like “January 8” would become “01/uary 8”. It is important in our example that the longest month formats are replaced first, followed by the shorter month format. So first replace “January” with “01/” and only after that replace “Jan” with “01/”.
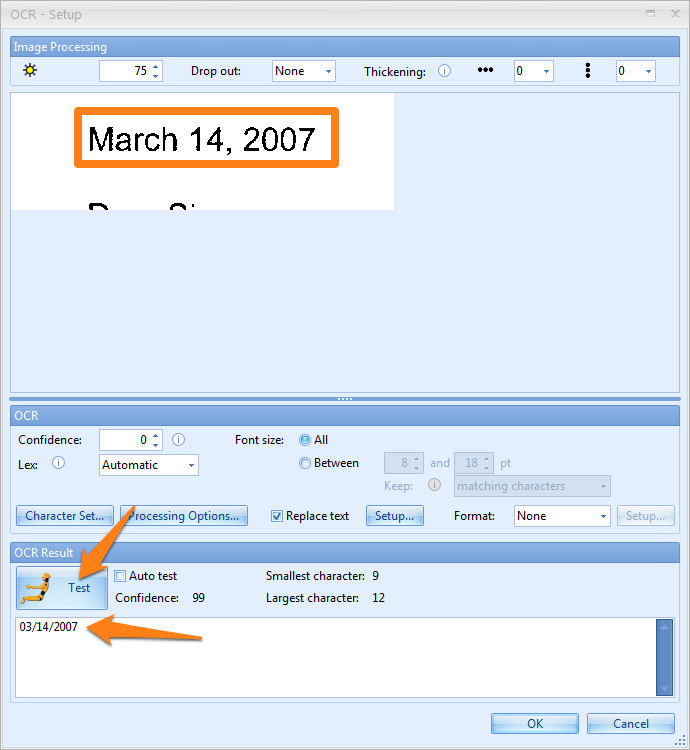
Test: The result after enabling and setting up the Replace text option can be tested by pressing the Test button (button with the yellow test dummy icon). Because we do not know the zone that the user will select during validation, the test will be applied on the zone defined in the Zone menu.
As you can see below, March 14, 2017 is converted to 03/14/2007.
05 Rubber Band OCR - Format
There are 3 types of Format options:
1) None: disables any formatting
2) Date: dates can be written as “02.06.17”, “2/6/2017”, “02-06-2017”, etc… By enabling the Format Date option, you can make the date format consistent. Press the Setup button to access additional options.
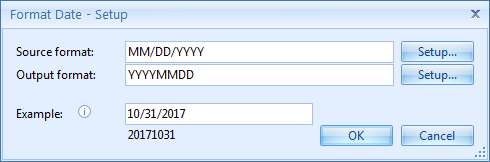
Source format: here you enter the format that matches the Source date, for example, MM/DD/YYYY. You can also press the Setup button to select different format types to compose your date format.
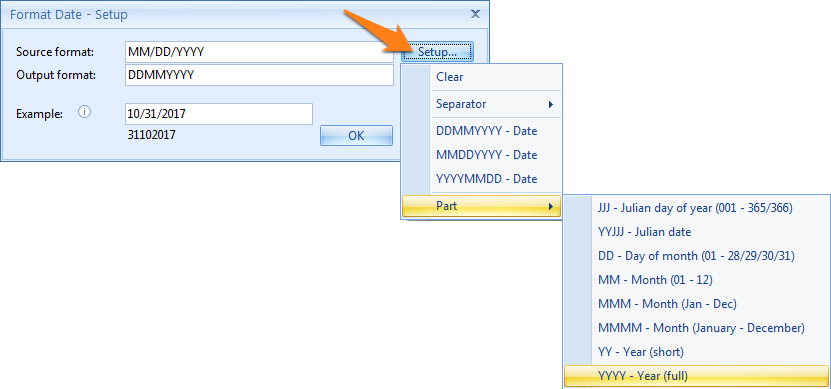
Output format: here you enter the format of the output date, for example, YYYYMMDD, without separators. You can also press the Setup button to select different format types to compose your output date format.
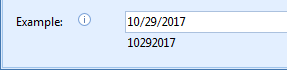
Example: here you can enter a date to test the date format. The result is displayed below the input field.
3) Amount: numbers can be formatted as “123000.5060”, “123,000.51”, “$123’000.51”, etc… By enabling the Format Amount option, you can remove the thousand separators, remove any currency symbols and normalize the decimal point to make the number format consistent. Press the Setup button to access additional options.
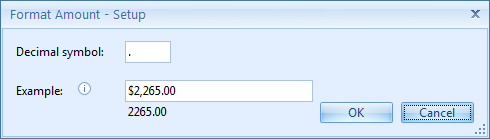
Decimal symbol: here we can enter the decimal symbol for the output format. The most frequently used symbols are “,” in Europe & Latin America and “.” in US, Canada, United Kingdom, South Africa, Australia, etc…
Example: here you can enter a number to test the Amount format. The result is shown below.
06 Check & Sticky Settings
TIP: The thumbnail on the right will follow you, so you can easily refer to the Setup window. Click on the thumbnail to make the image larger.
01 - Always check: enable this option to force the user to check the index field whether the value is valid or not. This is useful to double check critical values that are extracted automatically from the document using OCR.
First document only: this is a sub-setting of the Always check option and is only available when Always check is enabled. This is often used in conjunction with the Sticky option in Automatic mode and Stay sticky between batches. The user can select the initial value on the first document of a batch which will be applied to all other documents in the batch automatically.
For example, you want to scan a set of invoices. Assume that “Fiscal Year” is an index field set to Always check / First document only in combination with Sticky Automatic and Stay sticky between batches enabled. When the Validation screen opens, it will show the first document and will display the Year value of the last batch (Stay sticky between batches). This value can be accepted or changed. All the other documents in the batch will then use the same Fiscal Year value (Sticky Automatic) as the one selected for the first document and it won’t be required to confirm the Fiscal Year for the other documents in the batch (Always check / First document only).
02 – Required: enable this option when the index field MUST hold a value. Leave it disabled when you want to allow the user to leave the field blank.
Check if blank / Check if not blank: this is a sub-setting of the Required option and is only available when Required is disabled. Enable this option when you want to force the user to check when the index field is blank or when it is NOT blank. The user can then accept to keep the field blank or adjust it by entering a new value.
Use case “Check if not blank”: Assume 3 different document types. And one of the 3 document types has a date while all the others don’t have a date. So the field is not-required. However when there is a field value, the user wants to check if the correct date was extracted. In other words “Check if not blank”.
03 – Lines: here you can specify the Minimum and Maximum number of lines the multi-line text index value may hold.
Check if line count is less than maximum: when enabled, the user will be forced to check the field if the number of lines is less than the defined Maximum. At that moment, the user can still accept the original values or correct them.
Use case: If there can be a maximum of 10 invoice numbers listed and if less than 10 invoice numbers are extracted, then we want the user to check if any numbers are missing because of an OCR mistake for example.
04 - Level: there are 2 possible Level options:
1) Document (Default): every document can have its own unique index value
2) Batch: all documents have the same index value. If, during validation, you change the data for any of the documents in the batch, it changes for all other documents automatically. The last change applies to all the documents in the batch.
Important: What is the difference between Batch level index field and Sticky document level index fields?
Batch level index fields are different from document index fields with the Sticky / Automatic option enabled. With the Sticky / Automatic option the index value stays the same for a consecutive sequence of documents until the value changes.
After the index value changes, following documents will use that index value until the value changes again. Batch level fields are the same for all the documents in the batch. The last change applies to all documents, after or before the document with the last changed value.
05 - Sticky: Sticky options are only available for Document level fields. Press the drop-down arrow to select one of the 4 Sticky options:
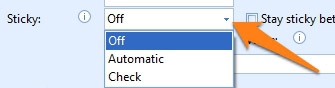
1) Off: the Sticky option is disabled.
2) Automatic: the last extracted or typed value is applied to all following documents having a blank index value until a document is detected with a different value. Then the new value is applied the next documents with blank index values and so on.
3) Check: same as Automatic, but this forces the user to check the index field when a sticky value is applied to a document with a blank index value.
Difference between Always Check and Sticky / Check: assume you have an index field called Document Type. The document type is automatically extracted with OCR extraction rules. Documents without a document type have the same document type as the preceding document. However, the document quality is not so good and OCR extraction of the document type is not 100% accurate. So the document type could be blank for two reasons:
1) There is really no document type and the last detected document type should be used.
2) There is a document type but automatic extraction failed to find it, in that case the document type should be selected manually.
This is a good situation to use Sticky / Check mode. In Check mode, the user won’t have to check the documents with an automatically extracted document type, but he will need to check the blank document types which were taking over the last used document type index value to be sure it was really blank and not related to an extraction problem. This is different from Always check. With the Always check option enabled, the user will have to check all the documents, including the documents with automatically extracted document types.
4) Counter: this option is only available for Text and Number index fields. With Counter index fields, you can create a custom counter which can be used for Bates numbering of legal documents, for example. The counter value can then be printed on the image with the Digital Imprinter.
Counter also has two sub settings: Start Value and Step. The step value can be negative to define a decremented counter.
Stay sticky between batches: this is a sub-setting of the Sticky option and is only available when Automatic or Check is enabled. Enable this option when you want the system to remember the last used index value of the previous batch. The last used value is stored on disk, so even if you restart the PC, it will be remembered.
For example, if you have an index field called Fiscal Year, it can be remembered across batches. The last used value, say 2018, is stored on disk.
So, the scan system can be switched off, and when a week later the user wants to scan some additional documents, the Validation screen will present 2018 as the proposed value for the Fiscal Year. This value can be accepted or changed. If changed, then the changed value will be stored and presented during the next scan session.
Value: this shows the last stored index value when Stay sticky between batches is enabled. You can modify this value if needed.
Uppercase: with this option enabled, manually entered text or text selected with the rubber band OCR tool will always be uppercase regardless of the state of the SHIFT or SHIFT LOCK keys on the keyboard.
07 Type
Press the dropdown button to select an option. Most of the options are self-explanatory check-sums, like VAT number checks in Europe, ABN in Australia, CNPJ in Brazil, etc.. A popular check-sum, for example, is the Luhn or “modulus 10” algorithm used to check credit card numbers, IMIE mobile phone device codes, etc
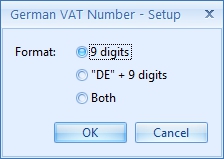
In some cases, like the German VAT number, we can also choose between a few options by pressing the Setup button.

The Setup window opens and you can choose which format you would like to use.
01 - Format: A format is like a regular expression mask to check if the extracted or manually entered value is correct and matches the mask. However, you don’t need to use the complex regular expression syntax. Instead, when you press the Setup button, you can construct your format by selecting the elements you need from an easy to use formatting pick list.
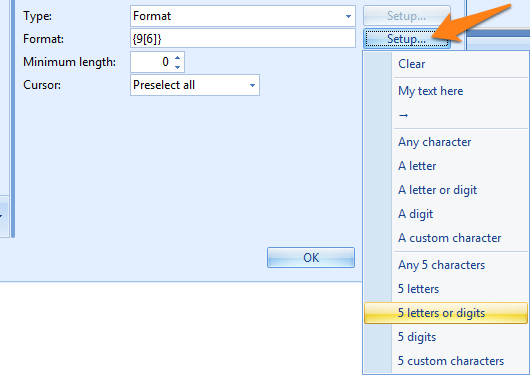
1) Clear: clears the mask
2) My text here: an example text. You can overwrite the example text with your own text if your Format consists of fixed characters. It’s also possible to enter text directly into the Format box.
3) -> : represents a long space. Long spaces are defined in the Rubber Band OCR Processing options.
4) A letter: shown as {A}, any letter is allowed, both upper and lower case. If you want to only accept a specific case, you can use a custom character.
5) Any character: shown as {?}, any character is allowed.
6) A letter or digit: shown as {X}, any single letter or digit is allowed.
7) A digit: shown as {9}, any single digit is allowed.
8) A custom character: shown as {C}, only allows defined custom characters. You can adjust these in the Custom Character Setup (more details below).
9) Any 5…: the number 5 is just an example, replace the 5 with the number of characters you want. For example: {?[6]} means any 6 characters, {A[2]} means 2 letters, {X[5]} means 5 letters or digits,…
Custom: by pushing the Custom button, you can choose the custom characters represented by the {C} element(s) in your format.

The Custom Character Setup window opens.
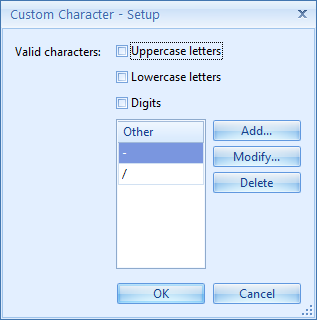
Above custom character definition only allows a – or / for every C element in your Format.
1) Valid characters: you can choose if the engine should return formats that are Uppercase letters, Lowercase letters or Digits.
2) Other: here you can add, delete or modify specific custom characters. In the example above, a custom character can only be a – or /.
Minimum length: If you want to read partial formats, set the minimum length lower than the total length of the format. The maximum length is set by the total length of the format. To explain how the Minimum length setting works, consider the following format:
{A[2]}{C}{9[8]}-{9}
Minimum length = 11
Maximum length = 13 (2 Alpha + 1 Custom + 8 Digits + 1 Hyphen + 1 Digit)
Examples:
AB/15687945-2:
OK because the number of characters is greater or equal than the defined minimum of 13 and the value starts with 2 letters followed by a custom character (“/“ in this case), 8 digits, a dash and a single digit.
AB/15687945:
OK because the number of characters is equal to the defined minimum length of 11 and all the characters comply to the format.
AB/15687945-02:
NOT OK because longer (14 digits) than the total length of the defined mask, if you want to accept words containing more digits, you need to increase the length of your mask. In this case “{A[2]}{C}{9[8]}- {9[2]}”, would make this value acceptable.
4B/15687945-2:
NOT OK because it contains another type of character than a letter in the first 2 characters and therefore does not comply with the defined format.
02 - Matching file:
Matching file only works with multi-line fields. It uses the content of the multiline field to check the existence of files in a folder. In our example, we can check if TIF files exists with the same names as listed in the multiline field.
Press the Setup button to edit the Matching file option.

The Setup window opens.
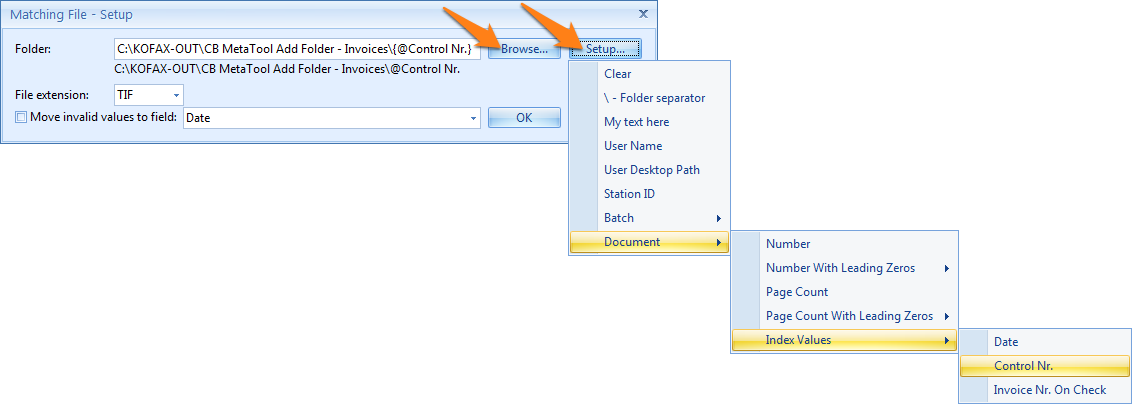
Folder: here you can enter the folder path containing the files you want to compare with the text value. Press the Browse button to select the folder you want to use. You can also manually enter the folder path. Press the Setup button to select different elements to compose your folder path.
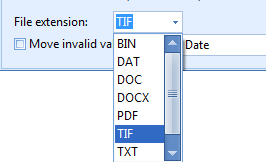
File extension: here you can specify which type of file(s) needs to be present in the specified folder. Press the dropdown button to select your required file extension or enter the extension manually.
Move invalid values to field: here you can set an index field to hold the values that did not match any file names in the folder.
Press the drop-down arrow to choose the index value. An interesting use of this feature, is to send an email, using the Email Export Connector, with the files that were not found.
In context of our example, the multi-line field contains all invoice numbers related to the AP Check. With the Matching file option we locate the TIF image for each invoice. If we can’t find the TIF images for one or more invoices, we put the missing TIFs in a field so we can communicate the missing invoices via email for further follow up.
Disable it if you don’t want to use this feature.
08 Cursor
There are 3 possible cursor options:
1) Preselect all (default):when the user navigates in the index field, the value is selected. When the user starts typing, the existing value is completely overwritten with the new value.
2) In front:when the user navigates in the index field, the cursor is positioned in front of the value in the field. When the user starts typing, the new value is inserted in front of the existing value. When “Cursor in front” is used in combination with Rubber band OCR, a space is appended after each rubber band OCR result. In that way, you can build a string of words by rubber banding different selections in a text.
3) At end:when the user navigates in the index field, the cursor is positioned after the value in the field. When the user starts typing, the new value is appended at the end of the existing value. When “Cursor at end” is used in combination with Rubber band OCR, a space is inserted in front of each rubber band OCR result. In that way, you can build a string of words by rubber banding different selections in a text.